
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 백준#BOJ#14501#퇴사#브루트포스
- 백준#BOJ#12865#평범한배낭
- 백준#BOJ#1939#중량제한
- 백준#boj#16932#모양만들기
- 백준#BOJ#8012#한동이는영업사원
- 백준#boj#12755
- 백준#BOJ#2615#오목
- Today
- Total
순간을 성실히, 화려함보단 꾸준함을
대용량 데이터는 어떻게 관리해야 되는 걸까? 본문
안녕하세요.
오늘은 대용량 데이터 관리에 대한 글을 작성해보려고 합니다.
개발자분들이 운영하고 유지보수 하고 있는 일을 수행하고 있다면 시간이 지남에 따라 데이터베이스에 데이터들은 쌓이게 될 것이고 이는 용량이 커짐을 의미합니다.
당연히 과거에는 데이터를 조회하는 시간이 빨랐음에도 데이터가 쌓이게 되면 느려지게 되겠죠.
또한, 한계가 있는 물리 저장공간 특성상 용량이 커지게 되면 이를 감당할 수 있는 스팩이 부족해집니다.
결국은 조회를 더 빠르게 수행할 수 있도록 SQL 튜닝을 실행하거나 많은 데이터들이 저장되어있는 공간을 나눈다거나 하는 방법들이 필요하게 될텐데 오늘은 이를 한번 다뤄보도록 하겠습니다.
크게 샤딩이라는 기법과 파티셔닝 기법이 있습니다.
샤딩
대량의 DB 데이터를 다른 물리 시스템에 분할하여 저장하는 기술
즉, 많은 데이터들이 저장되어 있는 DB 를 반으로 쪼개서 관리한다는 뜻입니다. 각 데이터베이스에 저장되어있는 데이터들이 분할 될 것이고 그만큼 저장공간도 확보되며 조회성 쿼리도 빠르게 개선이 되겠죠.
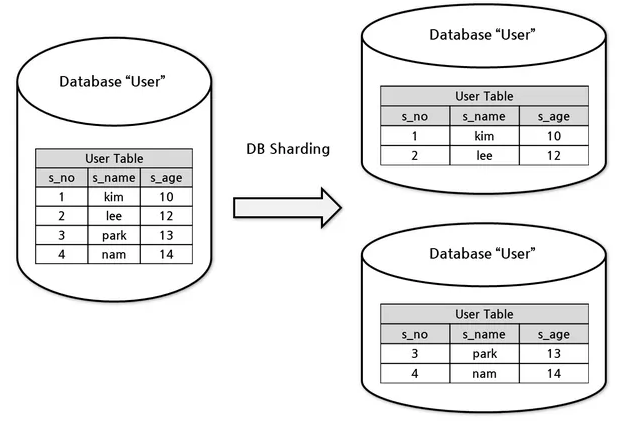
다만, 샤딩이라는 기법은 단순하게 적용할 수 있는 기법이 아닙니다. 데이터베이스 서버를 하나 더 구축한다는 뜻은 그만큼 비용이 든다는 것을 의미합니다.
서비스를 유지하기 위한 서버들이 존재하고 각 서버들은 많은 양의 비용을 지불하게 됩니다. 요새는 온프레스미 환경이 아닌 클라우드 환경에서 서버들을 많이 구축하는데 AWS 만 해도 비용이 만만치 않게 매달 발생합니다.
이런 상황에서 현재 회사의 사정상 데이터베이스를 하나 더 늘린다는 건?? 결코 쉽게 선택할 수 없는 선택지 입니다.
파티셔닝
대량의 데이터 테이블을 테이블 분할을 통해 저장하는 기술

한 테이블 내에 굉장히 많은 데이터가 있다면 이 테이블을 쪼개는 방식입니다.
이때 수평적 분할과 수직적 분할로 나누어서 정의할 수 있습니다.
수평 파티션닝
- 레코드를 기준으로 분할하여 특정 범위만 조회하여 성능을 개선하는 기법(샤딩과 동일한 개념)
- 장점 : 테이블당 데이터 개수가 작아지고 따라서 Index 개수도 작아져 성능이 향상된다.
- 단점 : 테이블간 join 연산이 증가해 조회성 시간이 증가 될 수도 있다.
수직 파티셔닝
- 테이블의 모든 컬럼 중 특정 컬럼을 쪼개서 별도 저장하는 형태, 하나의 엔티티를 2개 이상으로 분리
- 장점 : 자주 사용하는 컬럼을 분리하여 성능이 향상, 컬럼 수가 축소 됨으로 디스크 I/O 이점
- 단점 : 파티션 키 값 변경에 대한 별로 관리 필요
인덱스
인덱스에 대해서는 DB 를 접해보신 분들이라면 당연히 다들 알고 계신 내용이겠지만 세분화해서 정의를 해보려고 합니다.
데이터가 많은 테이블들에 대해서 빠르게 소수의 데이터를 찾고 싶을때 사용하는 것이 인덱스 인데요, 흔히 색인이라고 불리며 책의 맨 마지막에 특정 단어가 포함되어있는 페이지를 알고 싶을때 사용하죠.
장점 - SELECT 문을 이용하여 검색하는 속도가 빠릅니다. 다만 주의할 점은 찾으려고 하는 데이터가 전체 데이터의 소수여야 합니다.
단점 - 인덱스를 저장할 수 있는 테이블을 별도로 선언해야 합니다. 따라서 추가적인 공간이 필요하게 됩니다. SELECT 문이 아닌 변경작업(INSERT,UPDATE,DELETE) 가 빈번하게 발생하면 오히려 성능이 나빠집니다.
주의할 점은 인덱스를 사용해서 조회하면 언제나 항상 빨라지는 건 아니라는 것 입니다.
인덱스를 사용해서 찾으려고 하는 데이터가 전체의 10% 가 넘으면 오히려 Full Scan 을 하는 것이 유리합니다. 그럼 이는 사용자가 매번 쿼리문을 작성하려고 할때마다 사용자가 분포도를 계산하고 index scan 을 적용할 건지 full scan 을 적용할 건지 알아야 되는 걸까요??
다행이 모든 데이터베이스에는 옵티마이저라는 SQL 을 최적으로 실행시킬 수 있는 엔진이 존재합니다.
그래서 옵티마이저가 알아서 판단하고 적용시켜주게 됩니다.
클러스터형 인덱스(Clustered Index)
- 클러스터링이라는 단어는 보통 여러 개를 하나로 묶는 다는 것을 의미합니다. 클러스터형 인덱스란 단어도 마찬가지로 테이블의 레코드를 비슷한 것(프라이머리 키를 기준)들끼리 묶어서 저장하는 형태로 구현된 것을 의미합니다.
- 프라이머리 키 값에 의해 레코드의 저장 위치가 결정됩니다. 이는 데이터의 프라이머리 키 값이 변경되면 데이터 파일에 위치한 저장 위치도 변경되어야 함을 뜻합니다.
- 즉, 간단히 말하면 클러스터형 인덱스는 테이블의 데이터가 인덱스의 순서대로 물리적인 디스크에 저장되는 방식입니다.
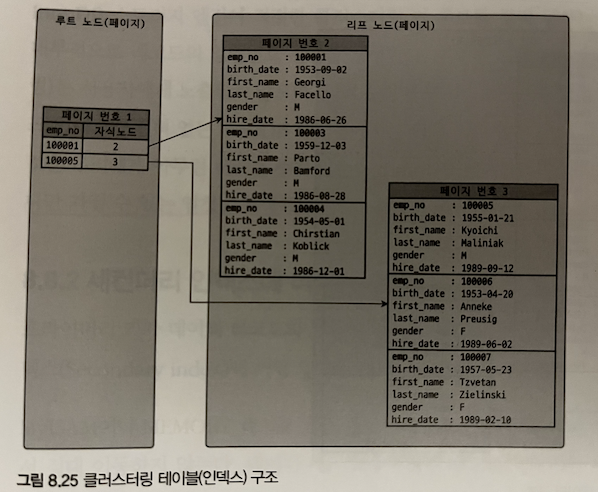
클러스터링 테이블의 구조 사진을 보면 일반적인 B-Tree 인덱스와는 달리 인덱스가 위치해 있는 노드에 모든 데이터들이 함께 저장되어 있는 것을 확인할 수 있습니다.
논클러스터형 인덱스(Non-clustered Index)
- 클러스터형 인덱스와 달리 논클러스터형 인덱스는 인덱스와 데이터가 별도의 위치에 저장됩니다.
- 데이터 레코드의 순서가 인덱스 엔트리 순서와 관계없이 저장되어 집니다.
이렇게만 보시면...클러스터형 인덱스랑 논클러스터형 인덱스랑 무슨차이인데???하는 생각이 들 수 있습니다.
그래서 한번 예시를 들어 비교해보겠습니다.
[상황] 직상 상사가 A 사원과 B 사원에게 인사 자료를 주면서 '이름' 으로 찾기 편하게 정리하라고 시켰습니다.
1. A사원 - 자료들을 이름 순으로 순서대로 정리합니다.(Clustered Index)
B사원 - 현재 자료에서 각 이름이 어디에 위치해 있는지 연습장에 따로 적어놓자(Non-Clustered Index)
2. 상사가 사원들에게 '고길동' 이라는 이름을 찾아 달라고 요청
A사원 - 순서대로 정리되어 있어서 빠르게 전달
B사원 - 연습장에서 해당 이름이 적혀있는 위치를 확인한 뒤에 자료를 찾고 전달
결론 : 단일 조건에 대해서는 둘 다 빠르나, A사원이 약간 더 빠릅니다. (Clustered Index)
3. 상사가 사원들에게 (가)~(다) 사이의 성을 가진 이름들을 찾아 달라고 요청
A사원 - 정렬되어 있는 자료들 중에서 (가)~(다) 까지 범위를 잘라서 전달 (Clustered Index)
B사원 - 연습장을 확인하고 자료위치를 확인하는 행위가 반복됨 (Non-Clustered Index)
결론 : A사원이 매우 빠름 (Clustered Index)
4. 상사가 사원들에게 '박보영' 이라는 자료를 추가해서 정리 요청
A사원 - 정렬된 자료에서 추가된 사원의 자료를 넣어야 될 위치를 파악하고 자료들 사이에 공간을 만들어 추가해야됨. 재정렬이 필요함 (Clustered Index)
B사원 - 자료를 그냥 추가하고 연습장에 추가된 사원의 자료 위치를 기록 (Non-Clustered Index)
결론 : 변경작업에 대해서는 B 사원이 빠름 (Non-Clustered Index)
5. 상사가 이름뿐만 아니라 나이도 찾기 편리하게 정리하라고 요청
A사원 - 이미 이름으로 정렬된 자료이기 때문에, 나이를 기준으로 기존 형태를 유지하며 정렬할 수 없음
B사원 - 나이 관련된 위치가 기록된 연습장을 하나 더 추가
결론 : B사원 (Non-Clustered Index)은 인덱스를 하나 더 추가 가능하지만, A사원 (Clustered Index) 은 불가능
[최종결론]
클러스터형 인덱스는 데이터 조회에 대해서는 빠른 성능을 보입니다. 그러나 테이블당 하나의 인덱스밖에 생성하지 못하는 단점을 안고 있습니다.
논클러스터형 인덱스는 데이터 조회에 대해서는 느린 성능을 보이지만, 변경이 빠르고 한 테이블당 다수의 인덱스를 생성할 수 있다는 장점을 가지고 있습니다.
대용량 데이터 삭제 방법
일반적인 DELETE 구문은 WHERE 조건을 사용해서 삭제하는 명령입니다. where 절을 사용하지 않고 삭제한다고 하더라도 내부적으로는 delete 구문을 사용하면 한줄한줄 일일이 제거하는 과정을 거치게 되어 느린 성능을 보입니다.
데이터를 빠르게 전체 삭제할 수 있는 방법은 무엇일까요??
1. DROP TABLE - 더 이상 테이블을 사용할 필요가 없다면 테이블 자체를 삭제시켜주는 방법이 있습니다.
2. TRUNCATE TABLE - 삭제 조건 없이 전체 데이터를 삭제하고 싶을때 유용합니다. 테이블 구조는 유지시켜줍니다.
그럼 전체 삭제 말고 wherer 조건을 추가하여 삭제하는 경우에는 빠르게 삭제할 수 있는 방법이 있을까요??
delete 구문에 top 문과 loop 문을 활용하여 루프를 돌리면서 삭제하는 방법이 있는데요, 이 방법은 각 데이터베이스별로 달라 지원이 되는지 안되는지 확인을 해보아야 합니다.
oracle 같은 경우는 익명 프로시저를 활용하여 FOR 문을 사용하여 지워주는 방법이 있습니다.
DECLARE
v_rowcount INT;
BEGIN
LOOP
DELETE FROM your_table
WHERE 조건
AND ROWNUM <= 10000; -- 한 번에 삭제할 행의 수
v_rowcount := SQL%ROWCOUNT;
COMMIT;
EXIT WHEN v_rowcount = 0;
END LOOP;
END;
지금까지 대용량 데이터를 어떻게 관리할 지에 대해서 알아보았는데요. 사실 이런 부분들은 직접 일을 해 나아가면서 느끼고 부딧치고 하나씩 경험을 통해 쌓는 방법이 제일인 것 같습니다.
감사합니다!!
'나의 개발 메모장' 카테고리의 다른 글
| [OSS] 나만의 Redis Command 만들어보기 (0) | 2024.04.27 |
|---|---|
| 긴 여정을 마치고....(토이 프로젝트 마무리) (2) | 2024.03.19 |
| 2023년 회고 (3) | 2023.12.30 |
| [Docker] docker-compose 첫 사용기! (0) | 2023.12.24 |
| 동시성 문제에 관하여... (0) | 2023.12.10 |


